The World of Neural Networks
By Isuru SudasingheThis article aims at readers who have not yet stepped into the world of machine learning. Although phrases like machine learning, artificial intelligence, neural networks are used very casually today, most people do not understand the basic idea behind them. In the world of machine learning, each term has its own unique meaning and there are relationships among each other that would be really helpful to clarify their purpose. Hopefully, you won’t get confused the next time you run into a buzzword like this.
To start the discussion, we need to look at the bigger picture of Machine Learning. All of this starts with Artificial Intelligence. Although my object is to go deep into machine learning, AI (Artificial Intelligence) is like the core domain of this field. AI can be defined in many ways depending on what extent you are willing to explore it. But for the sake of simplicity, we can say the development of computer systems that would normally perform by humans or beyond the capability of humans as Artificial Intelligence.
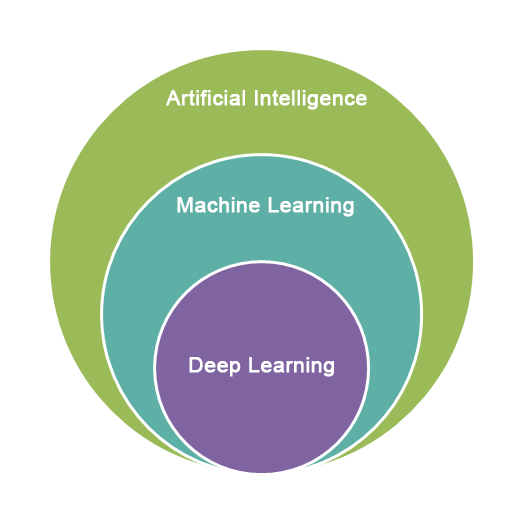
Then going a level deeper, we have Machine learning. Machine learning is a subdomain of Artificial Intelligence. Machine learning focuses on computer algorithms and data. Basically what machine learning does is create computer algorithms that improve with the use of data. The amazing thing about machine learning is that we only provide data to the algorithm and the algorithm will improve by itself when there is the required amount of data. Machine learning is related to AI by the relationship where ML (Machine Learning) creates algorithms that learn automatically that can be used by computers to simulate human behavior in a more advanced context. However, Machine learning is more familiar to us today not only its contribution to AI but also its applicability in many fields like Transportation, Healthcare, Agriculture, Information Technology to obtain an exponential increase in performance and accuracy.
Now to dive another level deeper we can follow the discussion in two paths. On one hand, we have classical machine learning which involves algorithms that learn and do predictions once we parse data, on the other hand, we have deep learning which involves layers of algorithms structured in a network to learn and make decisions on their own. In classical Machine learning, the accuracy of the prediction will increase with the amount of data available. However, once it reaches the limit of the algorithm, the prediction will not increase even when the dataset is further increased. In Deep Learning the prediction accuracy will keep increasing with the amount of data continuously. But the amount of data required for a deep learning model to produce an accurate result is much higher than that is required by a classical machine learning algorithm. So there is a trade-off even though deep learning produces better results.
Classical Machine learning has four categories. They are supervised semi-supervised, unsupervised, and reinforcement learning. Before exploring these subdomains, there are some keywords that one must get familiar with, in order to grasp what is going on. First, we have the term ‘label’. Label, labeled data set, or labeling all point out to the group of data that we would predict in our algorithm. A labeled data set is a cluster where we already know the output of our prediction. Labeling a data set means filling out the output column of a dataset that we have. Then there is the term ‘training’. This refers to the process of feeding data into the algorithm so it can process the data and learn in order to produce more accurate results.
Coming back to the topic, Supervised learning teaches the algorithm using a known example. The algorithms are fed with a labeled dataset. The algorithm identifies the patterns and makes predictions. Since the output is already given, the algorithm can rectify its mistakes during its training. There are three subcategories within supervised learning as Classification, Regression, and Forecasting. The classification does what its name says. It classifies data into categories. If someone has a dataset containing various physical attributes of plant leaves, then he can use classification to classify them into which type of plants they belong to. Regression learns relationships among data. For example, in a supermarket, a regression algorithm can be used to identify what items a person would likely buy if he already bought something like milk. Forecasting is predicting the future based on present data.
In semi-supervised learning, both labeled and unlabelled data are used. The main advantage here is that the algorithm can learn to label unlabelled data.
In unsupervised learning, the algorithm learns to grasp the patterns within data. Here there are no instructions provided to the algorithm as in previous cases. Instead, the algorithm is presented with a large set of data and it will learn to separate data into categories depending on their patterns. The concept of labeled input and output is absent in unsupervised learning.
Reinforcement learning focuses on regimented learning processes, where a machine learning algorithm is provided with a set of actions, parameters, and end values. By defining the rules, the machine learning algorithm then tries to explore different options and possibilities, monitoring and evaluating each result to determine which one is optimal. Reinforcement learning teaches the machine trial and error. It learns from past experiences and begins to adapt its approach in response to the situation to achieve the best possible result.
Since we roughly covered the basic points of Classical Machine Learning, we can now take a look into Deep Learning. As we have continued our discussion earlier, we know deep learning is also a subdomain of machine learning. But what makes deep learning is its unique way of layering algorithms into networks. And we have Neural Networks as a subdomain of deep learning. Now let’s explore the Neural Networks together so you won’t get jaw dropped the next time someone mentions it.
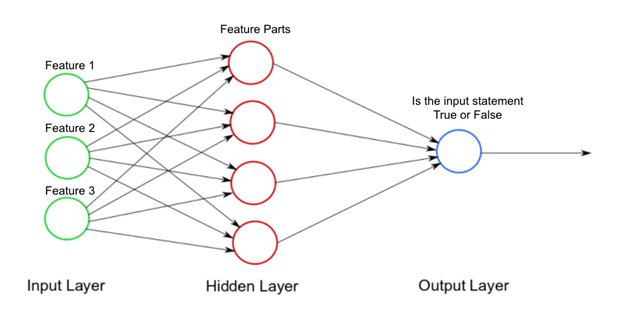
The inspiration behind the neural network is something like this. If we consider the handwriting of someone, unless he/she has the ultimate bad writing, we often can recognize the number of letters that person writes. I take number 3 as an example, the way 3 is written by ten different people can be very different. The slant of the character, the curves, edges, and lots of tiny details will be different in their writing. And even the two characters from the same person would have a significant difference between them. But the surprising thing is that our brain can understand a handwritten 3 in most cases. Every time we see a character, a set of neurons would get triggered in our brain causing a chain reaction. This chain reaction finally leads to the conclusion that we are seeing a number 3 at the moment. And the neurons that get triggers differ from character to character. Even for the same 3, separate neurons would get triggered when their appearance is not the same. This structure of the brain inspired the architecture of neural networks. Neural networks consist of layers. Each layer would contain a number of neurons. In a basic neural network, all the neurons in one layer are connected to each neuron in the other layer. And a neuron is simply a node in a layer that stores some value. And a neuron would get triggered by the values it receives from other neurons combined with a mathematical function called an “Activation function”.
A basic neural network can be sectioned into three parts. An Input layer, an output layer, and multiple hidden layers. Each layer would have a number of neurons. The number of neurons in the input and output layer is determined by the nature of the input and the output of the system. But there is no fixed procedure to determine the number of neurons in hidden layers. They are solely based on the practical nature and the context of the neural network.
When we dissect a single layer, each neuron in the layer would have a weight attached to it. When a neural network is trained the computer tweaks the value of these weights until the neural network produces the desired output. And in each layer, there is a bias value other than to all the neurons and weights combined. The bias value allows adding a constant to the network to further fine-tune the neural network other than using the weights. And the activation function is applied to the neuron by taking the summation of the value of neurons combined with their weight along with the bias from the previous layer. There are many activation functions in use like Sigmoid, ReLU(Rectified Linear Units), Softmax, etc. So the next time you see it, just keep in mind that it is just a mathematical function. This is the most basic structure of a neural network and there are multiple more advanced and complex neural networks used today. For example, a CNN(Convolutional Neural Network) is good for recognizing pictures while an LSTM(Long Short-Term Memory) network is good for speech recognition.
So the next question that we are going to explore is how hard is it to practically start coding and create an example neural network. Of course, there are methods to code a neural network from scratch. But thanks to the development in this area your life has become much more comfortable. Frameworks like Tensorflow, Keras, PyTorch now allow building Neural networks with every step possible.
Before trying an example neural network, there are a few more terms that you should get familiar with. First, we have the Cost Function. The basic idea behind the cost function is to get a value for the accuracy of the neural network while it is training. Then the objective of the training procedure would be to minimize the cost function i.e. increase the accuracy of the output. Even the Mean Square Root Error can be used as a cost function if we want.
Then there is gradient descent. As mentioned in the previous paragraph, the objective of the neural network is to minimize the cost function. Gradient descent is the algorithm to perform that minimizing task. To think of it intuitively, while climbing down a hill you should take small steps and walk down instead of just jumping down at once. Therefore, what we do is, if we start from a point x, we move down a little i.e. delta h, and update our position to x-delta h, and we keep doing the same till we reach the bottom. Consider the bottom to be the minimum cost point.
Next, we have the learning rate. Learning rate can be described as the length of the steps that we take when we go downhill in the earlier example. We can either take long steps and reach down fast or we can take small steps at each time and go slowly. Very high learning rates can cause people to miss the local minimum while a very low learning rate could take a long time to converge. Therefore, the learning rate must be selected carefully.
Do you remember the weights attached to neurons? And how it was described that the computer tweaks these weights to fine-tune the network. This process happens at the end of each iteration in the training phase and it is known as Backpropagation. And the talk about iterations brings us to the last two phrases batches and Epochs. When training the data, the dataset is divided into groups known as batches before sending them to the network. The objective is to generalize the content in the data set when training them. Once all the batches complete one training iteration, that set is known as an epoch.
Well, that’s pretty much it. Congratulations for making it this far. Now all you have to do is explore it on your own. If you want to learn how neural networks work in-depth, I strongly recommend the following 3 videos on youtube by the ‘3Blue1Brown’ channel. It’s one of the most easy-to-understand yet most elaborate explained content regarding a neural network out there.
- But what is a neural network? - Chapter 1, Deep learning
- Gradient descent, how neural networks learn - Chapter 2, Deep learning
- What is backpropagation really doing? - Chapter 3, Deep learning
If you are interested in jumping to coding right away, it would be easy to use python in the beginning. Mainly because of a large number of libraries available for python when it comes to Machine Learning. Even if your personal setup does not have python, you can use a platform like google CoLab or Kaggle. Especially Kaggle since there are many tutorials for beginners as well. The following link would provide a quick start for someone interested in coding their 1st Neural Network.