Let’s Understand the Compiler.
By Buddhika ChathurangaThis is the first article of the article series on developing a programming language from scratch. In this article, we are going to learn about the compiler. As software engineers, we all have heard about compilers. The compiler translates the source code (Java, Python, C#) into a target code (Machine code, Assembly Code, Byte Code).
There are many types of compilers. Let’s look at a few.
Transpiler (Source to Source compilers)
When a compiler gets a high-level language source code and translates it into another high-level language, we call it a transpiler.
Ex:
- Babel - a popular transpiler for JavaScript that can convert modern JavaScript code to an older version that is compatible with more browsers.
- TypeScript - TypeScript to JavaScript
Just-In-Time compiler (JIT compilers)
These compilers compile code during runtime, just before the code is executed. They are commonly used in dynamic programming languages to improve runtime performance. Ex: JIT in JVM
Ahead-Of-Time compilers
These compilers compile code before it is executed. AOT compilers are commonly used for statically typed languages such as C and C++.
Cross Compilers
These compilers are designed to run on one platform (ex. Windows) but generate code for another platform (ex. Linux). They are commonly used in embedded systems or in scenarios where the target platform is different from the development platform.
Single-Pass-Compilers
These compilers scan the source code exactly once and generate the object code or executable in a single pass. They are designed for simple languages with a small number of features and a linear structure, where it is easy to process the source code in a single pass. Examples of single-pass compilers include early versions of BASIC and Pascal.
Multi-Pass-Compilers
These compilers make multiple passes over the source code to perform various tasks such as lexical analysis, syntax analysis, semantic analysis, and code generation. They are designed for complex languages with many features and a non-linear structure, where it is difficult to process the source code in a single pass. Examples of multi-pass compilers include modern C and C++ compilers, which typically have multiple analysis and optimization stages.
Now let’s dive into the internals of a compiler. This will help you to understand the above compiler types more clearly. To translate source code into target code compiles, have several components. Refer to the below picture.
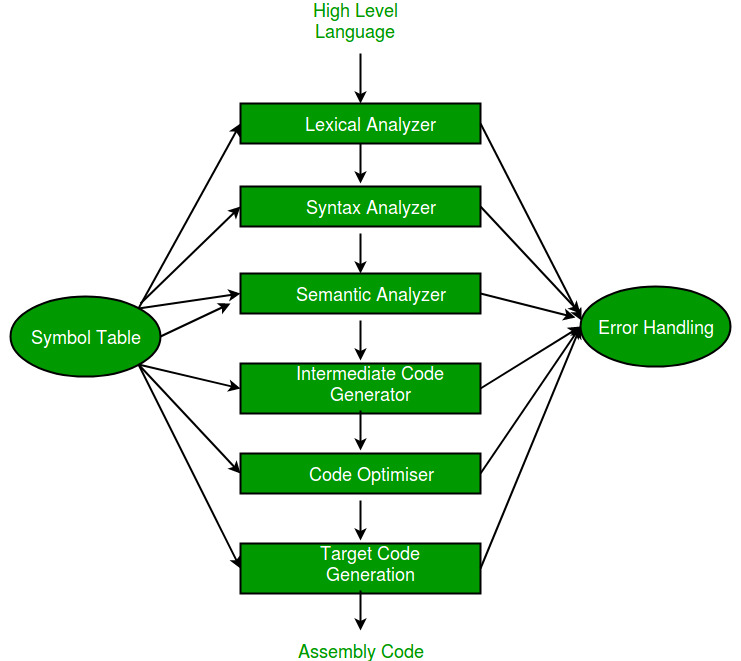
These components together work to translate source code to the target code. Now you know as mentioned in the image it’s no need to be the Assembly code every time at the end of the compiler. It may be any target code. Sometimes a high-level code, remember the transpilers?
Now let’s see how these components translate source code into target code. For that let’s use a real-world analogy, how human translators translate one language to another. Consider the following sentence.
He plays cricket
How do humans understand this sentence? When we look at the sentence, we can identify each word separated from space.
He => word 1 (token 1)
plays => word 2 (token 2)
Cricket => word 3 (token 3)
We call these tokens. Then we know these tokens are ordered in a known rule. Which is Subject Verb Object.
He plays cricket
[Subject] [Verb] [Object]
If there were any mistakes in the tokens or the order we can’t understand the meaning of the sentence. Now as humans, we are capable of that. But computers are not. We humans beans are intelligent to do that. Refer to the following image. Even though there is N number of spelling mistakes, still we can read that.

Again let’s go to our example. Anyway, if there were any mistakes in the tokens or the order the sentence became meaningless. Refer to the following sentence, which has correct tokens, but the wrong order.
Cricket plays he.
This sentence is meaningless. To understand the source code correctly compiler has to make sure that, the source code has the correct tokens in the correct order. In a compiler Lexical analyzer does the token verification part and a Syntax analyzer does the token order verification part.

We also call the syntax analyzer, the parser. As a result of parsing, syntax analysis happens. If there is any syntax error, we can’t do the parsing properly. As a result of parsing, we get a respective AST of the source code. AST means Abstract Syntax Tree. This is a tree data structure. The parser turns our source code into a tree data structure so that we can traverse the tree much easier than analyzing the source code as a string.
This is a sample AST.
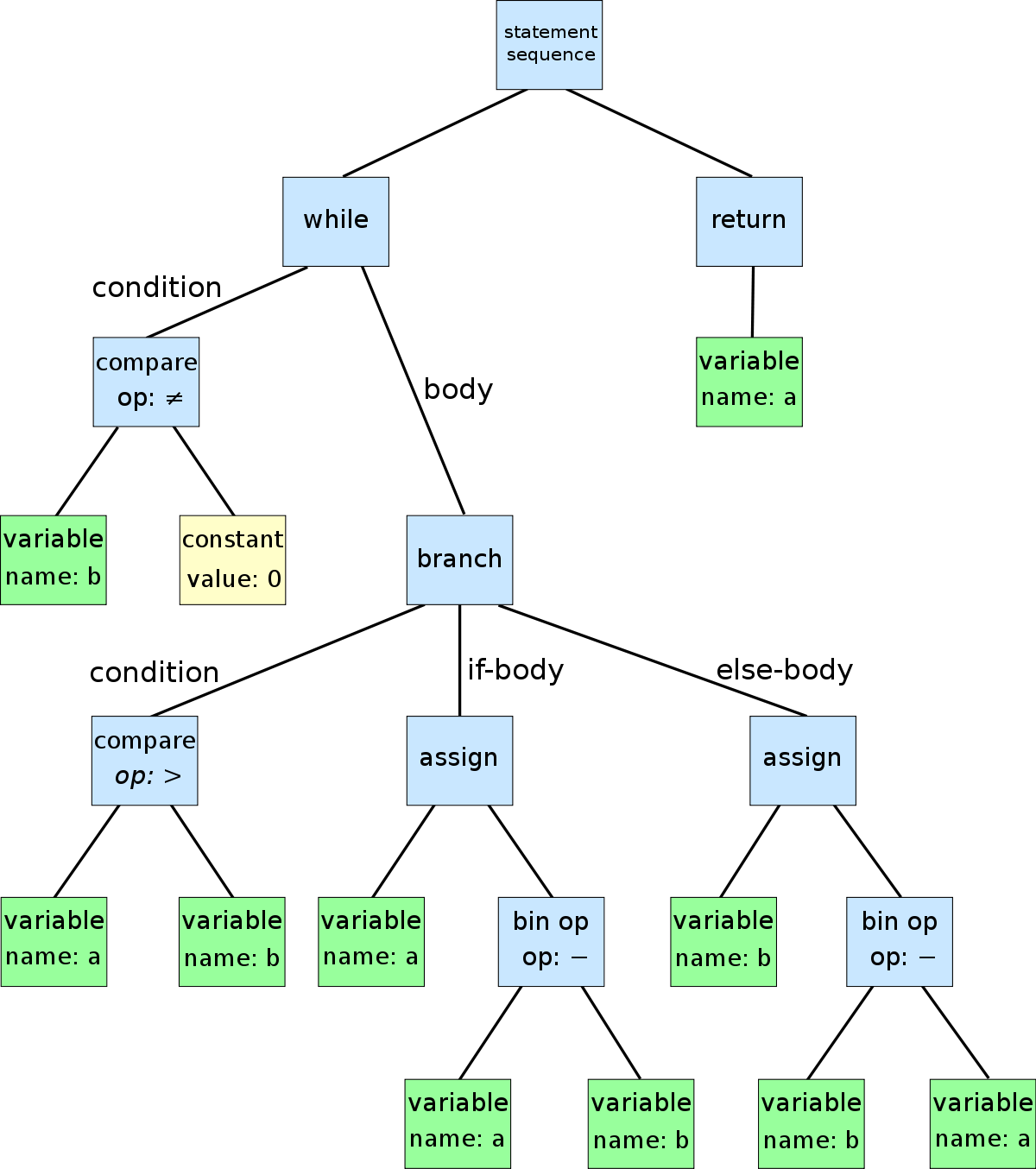
After the syntax analyzing stage, we come to the semantic analyzing stage. The semantic analyzer checks whether the program has a proper meaning. Look at the following sentence.
He plays apple.
Now in this sentence, all the tokens are correct and tokens are ordered in the correct order. That means this sentence does not have any spelling or grammar mistakes. But still, this sentence is meaningless. The Semantic analyzer checks this scenario. Look at the following code snippet.
int a = “Hello world, I am a String”;
Even though the above code snippet is syntactically correct, it’s semantically incorrect. A semantic analyzer can do this by traversing the AST. These are a few common compile-time semantic errors.
- Type mismatch
- Undefined variables and functions
- Duplicate declarations
After the semantic analyzer stage, we have an AST which can be used to generate the target code. But there are two more optional stages. Intermediate code generation and code optimizer. Let’s talk about those two stages briefly.
Before generating the target code why do we need an intermediate code? The reason is it is more standardized and its platform independent. So when we have the intermediate code we can use that to generate target codes for multiple platforms. Refer to the following image.
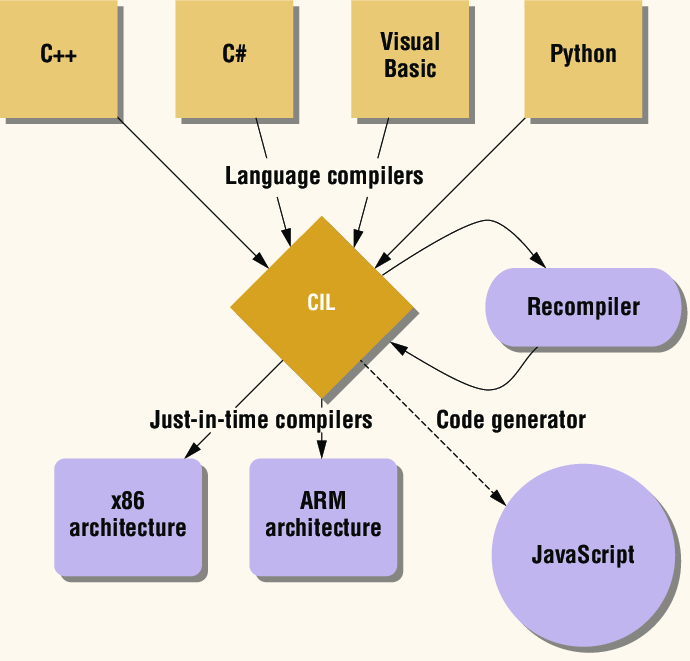
Here the CIL is the common intermediate language, which is a specification developed by Microsoft. When a source code is compiled to the CIL, then the next target code generation is already implemented. PL developers do not have to worry about that.
Code optimization in a compiler involves the application of various techniques to improve the performance, size, and efficiency of the compiled code. The goal of optimization is to transform the code generated by the compiler into an equivalent but better-performing form, without changing the functionality of the program. These are a few code optimization techniques.
- Constant folding
- Common sub-expression elimination
- Loop optimization
After the code optimization stage, the compiler generates the target code, which is runnable in a specific target platform.
Apart from the above stages, there are two other important components in a compiler. Those are the Error handler and Symbol table.
The job of an error handler in a compiler is to detect and report errors that occur during the compilation process, and to help the programmer understand and fix these errors.
When a compiler encounters an error, it usually generates an error message that describes the type and location of the error. The error handler is responsible for displaying this error message to the user clearly and concisely, along with any relevant information about the source code that caused the error.
The symbol table is an important component of the compiler because it allows the compiler to keep track of the various symbols used in a program and ensure that they are used correctly. By maintaining a mapping between each symbol and its attributes, the symbol table can help the compiler generate correct and efficient code, and can detect errors and inconsistencies in the program.
Now, this is a very high-level discussion of the compiler. This is another detailed blog post I have written about the compiler. In the next articles, I will talk about these components deeply. Until then happy coding.