Computer Vision - Magic Behind The Pixels
By Harsha De SilvaWhat is Computer Vision
One-third of the human brain is devoted exclusively to the task of parsing visual scenes. Even from birth, Human beings can understand the content from vision. A lot of learning and decision-making processes are based on those visuals. So, the fantasy of giving machines the ability to ‘see’ has been a hot topic for decades.
From a biological point of view, computer vision aims to come up with a computational model similar to the human visual system. From an engineering point of view, computer vision aims to build autonomous systems which could perform some of the tasks which the human visual system can perform. It tries to extract details from the pixels. In this aspect, Computer Vision is a subdomain of a broad area of Artificial Intelligence and Machine Learning. .
Deep Vision
However, within the machine learning field, there is an area often referred to as brain-inspired computation or neural networks which is inspired by the human brain since it is the best ‘machine’ for learning and solving problems. The human brain consists of billions of neurons that altogether connect to form a network. These neurons do the basis of all the decisions made based on the various information gathered. This is exactly what’s behind the Artificial Neural Network technique.
A neural network contains layers of interconnected neurons. A neuron in a neural network is a mathematical function that extracts and classifies information. When the number of “neuron layers” increases in a neural network, it is known as deep learning. This emergence of deep learning has added a huge boost to the already developing field of Computer Vision. Besides, the availability of large data sets, the invention of computers with higher GPU power, bigger networks, and faster machines have an impact on this advancement.
Typical Computer Vision Problems
-
Image classification: This is probably the simplest scenario. It categorizes a given set of images into pre-defined categories. For example, images with cats and dogs.
-
Localization The target in the localization problem is to locate the given object in an image. For example, in the given image, the ball has been localized. The typical way used to locate the object is to define a bounding box enclosing the object in the image.

- Object Detection This is a bit complex. The purpose of object detection is to localize and classify the objects in a given image.
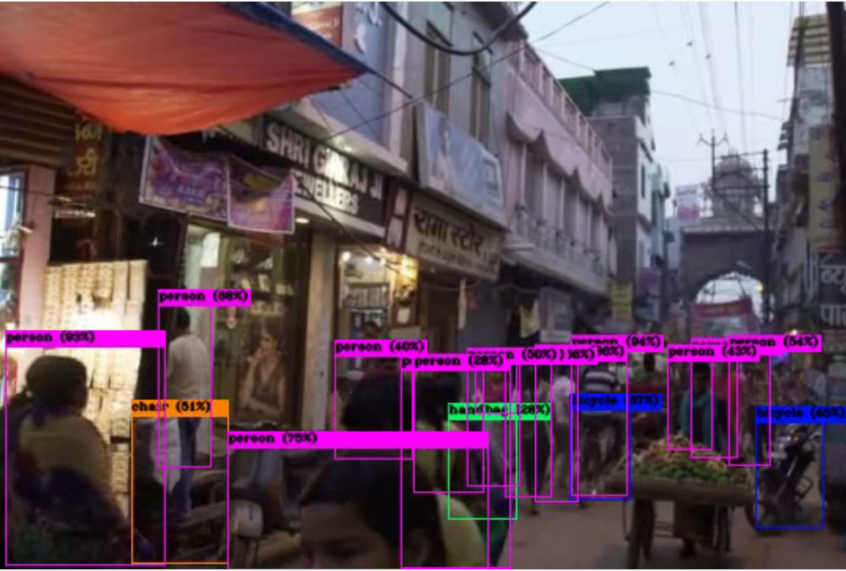
-
Object Identification Object Identification is almost the same as object detection. But in this case, the goal is to find the instances of a given specific object in an image.
-
Object Tracking Object tracking is tracking the motion of an object utilizing consecutive video frames as the input. For this, comparatively high computational power is needed. This can be done either by locating the object in each video frame and connecting them or locating the object once and learning the movement of the object.
How does it Work
Modern computer vision relies on deep learning. There are few steps when using a deep neural network for building a computer vision model. This approach is known as supervised training.
- Collecting Data
First, you would need a data set with annotated images. You can have your data set or use an existing one. Annotation is adding metadata to the image. It is the process of labeling or classifying an image using text, drawing tools, or both to show the data features you want your model to recognize on its own. For example, if you want the model to detect a certain image you have to first collect a training dataset containing images with that particular data set and draw bounding boxes and label objects in those images using an annotation tool.
- Extract Features
Feature extraction is a key point of the model. The entire deep learning model works around the idea of extracting useful features which help to identify the objects in an image. A feature in machine learning is an individual measurable property or characteristics of the problem instances that are considered. Those features are fed to the model as inputs when training the model. These features may include specific shaped colors or sizes and should be unique for that particular scenario. The features may vary for the type of model you are trying to build. For example, features needed for a face recognition problem differ from features needed for an object detection problem.
- Model Training
Training means feeding the dataset to the machine learning model, so it can learn using the features in the images fed. The target is to train that model so it can solve a fresh problem.
- Model Extraction
Then the model is tested using some testing data that weren’t used in the training phase. By doing so, the accuracy of the training model can be tested.
Commercial Applications
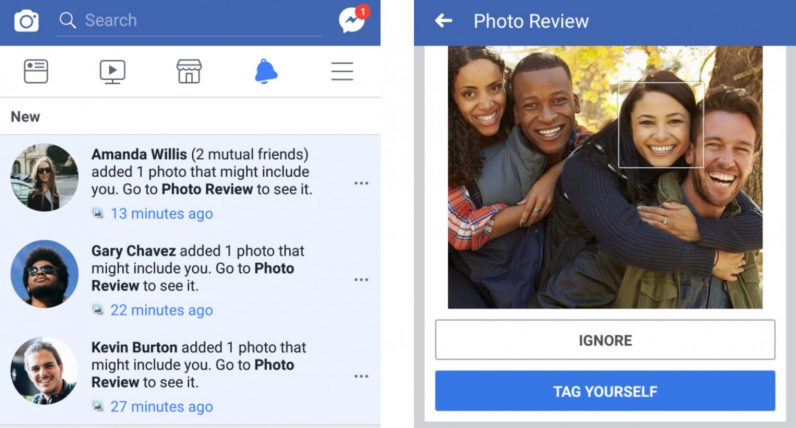
- Face Recognition by Facebook
This is a computer vision application that almost everybody is familiar with. This technology is beneficial against cyber-harassment and protecting the privacy of people.
Face recognition is used in many scenarios beyond social media such as security systems, mobile phones unlocking, smart advertising and attendance marking systems.
- Visual Search
Visual search engines like Google Images, Yahoo Image Search can retrieve images based on a provided image instead of keywords. Applications like Google Lens use computer vision to provide detailed information about a given image.
- Tesla Autopilot
Tesla Autopilot is an advanced driver assistance system introduced by Tesla. In there, they perform semantic segmentation, object detection, and monocular depth estimation to the row input obtained from cameras and use them to control the car. Thanks to this, the cars can adjust their speed depending on traffic conditions, brake when approaching obstacles, maintain or change lanes, take a fork in the road, and park smoothly.
Simple Exercise to try out: YOLO
YOLO, (You Only Look Once) is a highly accurate and fast object detection technology you can use easily. It applies a neural network to the entire image and divides the image into regions to predict the objects in it and their bounding boxes. Let’s try out a simple exercise with YOLO-V3 object detector to get a hands-on experience on object detection.
For simplicity, we are using an available pre-trained model to identify objects without training our image.
Since this involves machine learning and deep learning, an environment with high GPU power is required. You can use Google Collaboratory or your machine with Linux OS to try out the following example.
-
First You should have OpenCV, CUDA Installed in your environment.
- Then install Darknet
git clone https://github.com/pjreddie/darknet cd darknet make - For this exercise, let’s use an available pre-trained model which was trained on the ImageNet dataset. Download the weight file of the model.
wget https://pjreddie.com/media/files/darknet53.conv.74 -O ~/darknet/darknet53.conv.74 - The following commands will detect objects from an image and gives out the predicted output with confidence scores and boundary boxes. This output Picture would be saved as predictions.jpg by default.
!./darknet detect cfg/yolov3.cfg yolov3.weights <Image_Path> imShow(’predictions.jpg’) - To use in a real-time video stream, (If you are using Google Collaboratory, first grant access to the web camera)
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
Simple as that!
The above-used model is trained to identify 80 objects. (The list can be found in obj.names file)
You can use your dataset and train new models to detect any object you want. Additional Details can be found here.
Conclusion
The world is undergoing a deep digital transformation and computer vision plays an important role in it. But, despite all the technological advancements, the field of computer vision has many unsolved areas. Besides, one should give special consideration to ethical and privacy violations when using these technologies.